クローラーとは?なぜ重要なのかどんな仕組みなのか

クローラーとは?
クローラーとはウェブ上にあるテキストや画像などを取得し検索エンジンのデータベースへ登録させるために用いられるプログラムです。
クローラーもボットもスパイダーも同じ意味で呼ばれます。
クローラーの仕組みと重要性を理解するためには、検索したときに検索結果が表示されるまでを知る必要があります。
検索結果が表示されるまでにGoogle検索の流れは3つポイントがあります。
- クロール:クローラーと呼ばれる自動プログラムを使用して、ウェブ上で見つけたページからテキスト・画像・動画などをダウンロードする。
- インデックス登録:ダウンロードしたテキスト・画像・動画ファイルを解析して検索エンジンのデータベースへ保存します。
- 検索結果の表示:ユーザーがGoogleで検索すると検索クエリに関連したコンテンツを返します。
新規ページを作ったとしてもページを変更したとしてもGoogleのクローラーがページに訪れてくれない限りGoogleの検索結果に表示されませんし、ページは再評価されず検索順位は変わりません。
流入を増やすためにはいかにクローラーが訪れてくれてページをたくさんインデックス登録してくれるかが重要になります。
もう少しGoogle検索の仕組みを理解したい方は、Google検索セントラルのページがおすすめです。
今更ですがこれからの話はすべてGooglebotを対象にしています。
BingのBingbotやappleのApplebotなどありますが世界でも日本でも一番使われている検索エンジンはGoogeなのでここを押さえておけば間違いないかと思います。
クローラーの処理構造

- クロールキュー:XMLサイトマップや過去のクロールによって得られたURLをリスト化します。
- クローラ:クロールキューからURLを取得して、クロールが許可されているのかrobots.txtを読み込んで確認します。もし禁止されていた場合はHTTPリクエストをせずスキップします。
- 処理→レンダリング:ユーザーと同じようにコンテンツを確認するためページをレンダリングします。
- HTTPレスポンスした際にnoindexがあった場合はレンダリングを行わず終了します。
- noindexがなければ、レンダリングキューにいれられレンダリングを行います。
- サーバーサイドレンダリングのようにHTMLにすべてのコンテンツがある場合は問題ないですが、フロント側でJavaScriptを使用してHTMLを生成するような場合はJavaScriptを実行します。
- HTMLにリンクがあった場合はURLをクロールキューに追加します。
- インデックス:レンダリングをして得られたテキスト・画像・動画を検索エンジンのデータベースに保存します。
こんな感じでクローラーは処理を行います。
この後クローラビリティというクロールの効率化について話す際にこの処理を理解しておくと何のためにやるのかがはっきりします。
クローラーで抑えておくべきポイント
クローラーには限られたリソース(制限時間と制限容量と考えると分かりやすい)があり、すべてのページをクロールしてくれるわけではありません。
サイトに訪れてもページがたくさんあれば途中でやめてしまうことだってあります。
せっかくリライトしたのに中々インデックスされないなんてこともあります。
新規ページを公開したらインデックス登録してほしいし、更新したページも評価してもらわないと検索結果の順位は上がりませんよね。
どのくらい自分のサイトにリソースを割いてくれるか、効率化させてページをクロールしてもらうことが大切です。
クロールバジェットは限られている
Googleがサイトのクロールに費やす時間やリソースはクロールバジェットと呼ばれクロール能力とクロールの必要性の2つによって決められます。
サイトのクロールできる時間を決める要素と思ってもらってOKです。
クロール能力の上限
クロール能力とはクロールの頻度と言ってもよいかと思います。
クロール頻度とはサイトにやってきたクローラーがクロール時に行う1秒間当たりのリクエストの上限です。
リクエストを行えば必然的にサーバーはレスポンスするために処理をするため負担がかかりますが、Googleはサーバに負担をかけないようにクロールをしたいという考えがあるため以下の要素でクロール頻度を定めます。
- サーバーの対応能力:リクエストに対して迅速に応答してくれている場合は、接続数を上げ頻度を上げますが、応答が遅くなった場合やサーバーエラーが返ってきた場合は接続数を少なくして頻度を下げます。
- Search Consoleでの設定:Search Consoleでクロール頻度を減らすことができます。しかしクロール頻度を高めることはできません。
- Googleのクロール上限:Googleのクロールに使うマシンによって上限が決まります。
つまり、サーバーの強さやSearch Consoleの設定、マシンの上限によってクロールの頻度を調整します。
クロールの頻度が高ければ高いほどたくさんのページを素早く読み込んでくれるわけです。
ちなみに余談ですがクロール頻度をサイトにやってきてくれる回数と勘違いしないように気を付けてください。
クロールの必要性
他のサイトと比較して、クロールする時間・更新頻度・ページの品質・関連性を考慮してクロールに必要な時間を費やしています。
クロールの必要性は3つの要素できまります。
- 検出されたURLの数:クローラーはサイト上の認知しているURLすべてをクロールしようとします。
- 人気度:インターネット上で人気の高いURLほど情報の鮮度を保とうと頻繁にクロールされます。(人気度は被リンクの多さで決まる※自分の考え)
- 古さ:変更の反映に十分な頻度でクロールしようとします。
これはそのサイトをクロールする必要性があるのかを判断しています。
URLの数が多ければたくさんクロールしないとすべて把握するのは難しいと考えればURLが少なければそんなにクロールしなくてもいいと思えます。
人気がなければ必要性は低いですし、頻繁に更新しないのも必要性は低そうですよね。
クロールバジェットまとめ
クロールの能力が上限に達していなくても、クロールの必要性が小さければサイトのクロールは少なくなります。
クロールバジェットを増やす方法としてGoogleはこのようにアドバイスしています。
クロール バジェットを増やす方法
Google では、人気、ユーザー価値、一意性、配信容量に基づいて、各サイトに対するクロール リソースの量を決定します。クロール バジェットを増やす唯一の方法は、クロールの処理能力を高めること、そして何よりも検索ユーザーにとってのサイト コンテンツの価値を高めることです。
クロールの処理能力を高めるというのはサーバーが強くないと難しそうです。
ただ限られた時間・リソースでもクロール効率を上げることでたくさんのページをクロールしてもらうことが可能です。
これをクローラビリティと呼びます。
クローラビリティを高める方法がいくつかあるので紹介します。
※私のようにページ数が少なく更新もあまりされないようなサイトはクローラビリティを高める必要はありません。
更新したらインデックスリクエストが手動でできますし、すぐにインデックスされるからです。
大規模サイトや更新が頻繁に行われるサイトでは、時間・リソースの上限によりインデックスがなかなかされないこともあるのでクローラビリティを上げる必要があります。
クローラビリティを高める方法
クロール処理構造で紹介したフローの中でどこに時間・リソースがかかるかを理解すれば改善するべきところがわかるかと思います。
ポイントは、HTTPリクエストをしてレンダリングすることに時間やリソースの無駄を削減することと、クローラーが手広くページを巡回できるようにサイト内構造を適切にしてあげることです。
※リソースといったり時間といったりするとややこしいのでこれ以降はクロールバジェットとまとめます。
無駄なクロール時間を削減する
- 重複コンテンツをまとめる
- クローラーは認知しているURLをすべてクロールするため重複コンテンツであってもクロールバジェットを消費します。
- 重複コンテンツは301リダイレクト設定し正規化することでクロールバジェットを減らせることができます。
- robots.txtでURLのクロールをブロックする
- noindexの場合、HTTPレスポンスされた際にnoindexを確認するためクロールバジェットが無駄になります。
- 検索結果に表示させたくないようなページはrobots.txtでブロックすることで無駄が減ります
- 削除したページは404, 410ステータスコードを返す
- クローラーは認知しているURLをすべてクロールします。
- 404は対象URLを再度クロールしないように強く求めるので無駄を削減できます
- soft404エラーをなくす
- soft404エラーとはURLにアクセスしたときにページがないのに200ステータスコードを返すことです。
- この状況だと永遠にクロールされるため404ステータスを返すなどしてクロールされないようにしましょう。
- URLを簡潔にする
-
過度に複雑な URL(特に、複数のパラメータを含む URL など)は、サイト上の同じまたは同様のコンテンツを表す多数の URL が不必要に作成される原因となることがあります。その結果、クロールの際に問題が発生し、Googlebot が必要以上に帯域幅を消費したり、サイトのすべてのコンテンツがインデックスに登録されない状態を招いたりする可能性があります。
Google の URL 構造ガイドライン | Google 検索セントラル | ドキュメント | Google for Developers
-
Google公式より上記の記載があるので、簡潔なURLにすることをおすすめします。
-
- ページの読み込み効率を上げる
- クローラはレンダリングをするため画像や動画, CSS, JavaScriptなども読み込みます。
-
できる限り早くレンダリングできるようにすることでクロールバジェットを削減できクロールされるページを多くすることができます。
サイト内構造を適切にする
- サイトマップを最新状態に保つ
- 内部リンクの最適化
番外編
- 外部リンクをもらう
- クロールキューに入れられるのは自分のサイトだけではありません。
- 外部ページに自分のURLがある場合もクロールされるので訪れる頻度が増えます
- サーバーを最強にする
- サーバーが弱いと結局クロール頻度が低くされます。
- なのでつよつよサーバーを持っておけばその影響はないし、レスポンスも早いのでクロールバジェットの削減にもつながるのでは?と思っています。
まとめ
クローラとクローラビリティについてご説明いたしました。
更新しても新規ページを追加してもインデックス登録がされないと検索結果にあがってきませんし順位が上がることもございません。
大規模なサイトや更新頻度の高いサイトを運用しているのであれば一度チェックしてみてはどうでしょうか。
BERTアップデートとは?どんな仕組みでSEOへの影響を解説

BERTとは?
2018年にGoogleから発表された自然言語処理技術のひとつです。
自然言語処理というのは、人間の話ことばや言葉をコンピューターが分析処理する技術でコンピュータが人間の言葉を理解することです。
今はやりのChatGPTも自然言語処理の技術です。
BERTはBridirectional Encoder Representations from Transformersの略で、日本語だと「Transformerによる双方向のエンコード表現」と訳されます。
Transformerは構造なのでSEOのためだったら理解する必要はございません。
自然言語処理に興味がありよく会社で利用していましたが、Transformerに関して分かりやすく説明できる自信がないのでそこまで理解したい方は以下のサイトをご覧ください。
双方向のエンコードにより、文章の文頭と文末の両方から学習をして文脈を読み取れるようになりました。
2018年の当時は自然言語処理の分野においてかなり注目を浴びておりました。
2018年の年終わりくらいにBERTがオープンソースとして公開されております。
長ったらしくなりましたが、BERTとは人間の話し言葉や書き言葉の理解ができます。
なぜBERTが必要なのか?
2019年にランキングシステムにBERTが導入されたのですが、なぜ必要だったのか。
結論、音声入力のような話し言葉の検索クエリを理解できず、求められているコンテンツを適切に表示できなかったためです。
昔は「BERT 仕組み 必要性」など、検索エンジンを理解し検索エンジンのための入力方法がありましたが、スマホの普及や音声入力により検索エンジンには「BERTという仕組みがなぜ必要なのか」のような人間が使う話し言葉のクエリが増えてきました。
人間は理解できますが、コンピューターは複雑なクエリから意味を読み解くのはとても苦手です。
だから複雑なクエリにも対応できるBERTが必要となり導入されました。
Google検索の本質は、言語を理解し正しい情報を返すことです。
そのためには単語が特定の順序で結合されたときにどんな意味になるのか知る必要があります。
その点でもBERTは導入する必要性があったと思います。
例えばどんなクエリで効果を発揮するのか
BERTの効果について、上記ページで紹介されていましたので紹介いたします。
「2019 brazil traveler to usa need a visa.」2019年ブラジル旅行者から米国へはビザが必要という検索クエリですが、BERTが導入されるまではtoがどこにかかっているのか理解ができずブラジルへ旅行する米国民に関連するコンテンツが返されていました。

BERTを使用することでtoがどこにかかっているのか理解ができるようになりクエリに対してより関連性の高いコンテンツを提供できるようになりました。
そのほか色々例は載っていますので、興味がある場合はリンクに飛んでみてください。
RankBrainとBERTの違い
RankBrainとはクエリから検索意図を読み取って適切なコンテンツに関連付けをしてくれます。
例えば「サッカー 岐阜 結果」と調べるとFC岐阜の試合結果のコンテンツが上位表示されます。
このようにクエリに単語が入っていなくても検索意図から何を求められているかを判断し適切なコンテンツに関連付けをしてくれます。
BERTは、長いクエリや「to, for」などの前置詞が意味に大きく影響する検索などで正確に検索クエリを理解してくれるものなので、役割が違います。
BERTは日本にも導入されている
2019年10月25日にBERTに関して公式アナウンスがありましたが、2019年12月10日に日本語を含む70語以上のGoogle検索に展開されております。
BERTへの対策はあるのか
BERTへの対策は特にございません。
検索クエリを正確に理解してコンテンツを表示してくれるのが役割のためむしろ検索クエリに向けた品質の高いコンテンツを作っていたならば上位表示されるチャンスが増えるかと思います。
なのでユーザーにも検索エンジンにも理解できるコンテンツを作ることが大切かなと思います。
そのほかのコアランキングシステム
ヘルプフルコンテンツシステムとは?仕組みから詳細まで説明 - SEOと旅行とか
完全一致ドメインシステム(ExactMatchDomains : EMD)とは? - SEOと旅行とか
フレッシュネスシステム(Freshness system)とは?上位表示される仕組みを解説

フレッシュネスシステム(Freshness System)とは?
Google は、検索クエリに対してより鮮度の高いコンテンツが期待される場合にそのようなコンテンツが上位に表示されるように、「検索クエリにふさわしい鮮度」を評価するさまざまなシステムを導入しています。
Google 検索ランキング システムのご紹介 | Google 検索セントラル | ドキュメント | Google for Developers
検索クエリはその時々によって求められるコンテンツが変わります。
例えば「地震」クエリの普段の結果は地震対策などが求められますが、地震が発生して間もない場合はニュース記事などの情報が求められます。
これは瞬間的な鮮度ですが、常に鮮度の高いコンテンツが求められる時もあります。
例えばフレッシュネスシステムは時間経過とともにアップデートされていきます。
フレッシュネスシステムの5年前の情報よりもアップデートに対応した最新の情報が求められます。
このようにクエリによって、ふさわしい鮮度のコンテンツを上位表示してくれるのがフレッシュネスシステムです。
フレッシュネスシステムはどのようなテーマで適用されるか?
Googleは3つのテーマはフレッシュネスシステムと関連があると判断しております。
- 最近の出来事・注目な話題:最近のイベントやWeb上でトレンドになり始めた注目のトピックなど
- 定期的に繰り返されるイベント:年次イベントやスポーツ結果など
- 頻繁な更新:ホットトピックや定期的なイベントはない情報
具体的な事例をもとに説明します。
注意点ですが、あくまでもGoogleがこのテーマに関連したクエリはフレッシュネスシステムと関連性があると判断しただけです。
このテーマ以外のクエリでもフレッシュネスシステムの影響は受けます。
自分は勘違いして頭がこんがらがっていたので念のためお伝えしておきます。
最近の出来事・注目の話題
最近のイベントやWeb上でトレンドになり始めた話題が対象です。
お盆の期間に書いていましたが連休によってコロナが猛威を振るっており注目の話題となっています。
「コロナ」で検索すると上位には1日前や4時間前の最新情報が表示されるのは注目されているトレンドだからより鮮度の高い情報が求められているだろうとフレッシュネスシステムが評価した結果です。

ちょっと脱線してフレッシュネスシステムとQDFの違いについて
QDFとはSNSやニュースなどで特定のワードの検索ボリュームが急激に増加したとき、最新情報が上位表示されやすくなるアルゴリズムです。
QDFは特定のキーワードに限定されフレッシュネスシステムはキーワードが限定されておらず範囲の広さに違いがあると説明されていますが自分はよくわかりません。
SNSやニュースで特定のワードが急激に増加したワード(QDF)と注目の話題(フレッシュネス)にキーワードの範囲に違いがあるのか?と思います。
そもそもSNSやニュースの発信から注目の話題となるので一緒じゃないかと思います。
厳密には挙動が若干違うのかもしれませんが、トレンドに対して最新のコンテンツを上位表示するという考え方は同じなので、自分は一緒だと言っておきます。
※厳密には違うと思うんですけどね…(逃げ)
定期的に繰り返されるイベント
例えばオリンピックのように定期的に繰り返されるイベントです。
日本では今甲子園が行われているのでフレッシュネスシステムにより、古い甲子園の結果ではなくて、今開催されている甲子園の結果が適切な鮮度のコンテンツだと判断し上位表示されております。

フレッシュネスシステムが適用される「頻繁な更新」
更新頻度が高い情報で例えば気象情報や災害情報などが対象です。
今(2023年8月16日)だと、台風7号が接近し今どこに台風がいるのか天気はどうなのか最新の情報が求められているためフレッシュネスシステムにより最新情報が上位表示されております。
これ以外にも商品のレビューなんかもそうです。
レビューは頻繁に更新され検索するユーザーも新しいレビューを求めているためフレッシュネスシステムが適用されます。

鮮度がよければ上位表示されるとは限らない
SEO界隈ではGoogleは古いコンテンツよりも新鮮なコンテンツを好むという話がありますが、どんなサイトでも新鮮なコンテンツのほうが良いとは限りません。
「ナポリタン レシピ」のような時間が経過しても価値を失わない情報は鮮度が関係ありません。(このことをエバーグリーンという)
あくまでも時間が関係するコンテンツである場合は、上位表示に鮮度が影響します。

なぜフレッシュネスシステムが必要なのか?
フレッシュネスシステムが必要な理由は信頼性のためです。
現在はE-E-A-Tという考え方が非常に重要になってきており、Googleも信頼性の高いコンテンツを上位表示する傾向があります。
もし「SEO」というクエリで同じ信頼性を持った5年前の情報と1日前の情報があったとしたらどちらを求めますか?またどちらを信頼できますか?
1日前の情報のほうが今の技術に近く信頼できると思います。
E-E-A-Tは時間(鮮度)という考えがないので5年前と1日前の情報のどちらがユーザーに求められているのか理解することができません。
この時間(鮮度)を補うためにフレッシュネスシステム必要なのだと思います。
フレッシュネスシステムのために何をするか。
結論を話す前にMozのテストで興味深い情報がありました。
Mozでは2016年以来更新されていなかった自動車 SEOの記事で以下の変更を行いました。
- テキストを5%未満変更した
- タイトルタグに2022を追加した
- タイムスタンプを更新した
すると「自動車 SEO」というキーワードのランキングが3ページ目から1ページ目に移動したとのことです。

フレッシュネスシステムと関連する3つのテーマから外れた記事でもフレッシュネスシステムによって順位の影響を受けていると考えられます。
またLANYさんの記事でもMozのテスト結果を見てリライトしてみたところ効果があったようです。(クエリまでは書かれていませんでした)
弊社でも、1つのメディアでフレッシュネス施策を行ったところ、Google Search Consoleで、インプレッションとクリック数が過去3ヵ月で最大になった事例があります。実施した内容としては、記事の導入部分のリライトを全記事に実施しただけです。SEOで重要なフレッシュネスアルゴリズムとは?具体的な運用施策も解説 | 株式会社LANY | デジタルマーケティングカンパニー
このことから私たちがしなければならないことは、「このページの対策キーワードは時間が関係しているのか」と確認することです。
もし時間が関係するのであればフレッシュネスシステムの影響を受ける可能性があるので定期的にコンテンツを更新してべきです。
逆にNOと回答ができるのであれば、鮮度を気にせず今まで通りコンテンツの品質を上げることに取り組むできです。
そのほかのコアランキングシステム
RankBrain(ランクブレイン)とは? RankBrainの対策はないことまで説明 - SEOと旅行とか
完全一致ドメインシステム(ExactMatchDomains : EMD)とは? - SEOと旅行とか
ヘルプフルコンテンツシステムとは?仕組みから詳細まで説明 - SEOと旅行とか
BERTアップデートとは?どんな仕組みでSEOへの影響を解説 - SEOと旅行とか
ヘルプフルコンテンツシステムとは?仕組みから詳細まで説明

ヘルプフルコンテンツシステムとは?
Googleは以下のように記載しております。
ヘルプフル コンテンツ システムは、訪問者に満足感を与えているコンテンツを高く評価し、訪問者の期待に応えていないコンテンツとの差別化を図ることを目的としています。
Google 検索のヘルプフル コンテンツ システム | Google 検索セントラル | 最新情報 | Google for Developers
ユーザーに向けてオリジナルで役立つ有用なコンテンツを高く評価し、検索エンジンに向けたコンテンツは上位に表示しないアルゴリズムです。
ポイントは「ユーザーに満足してもらえるコンテンツ」であることです。
このポイントについてGoogleはすでに定義されていますのでご紹介いたします。
ユーザー第一に考えたコンテンツの指標
Googleには明確にユーザーを第一に考えたコンテンツとして言語化された基準があります。
以下の質問に「はい」と答えられるコンテンツであれば今回のアルゴリズムによっての影響はなく好影響であるかもしれません。
- 特定のユーザー層がすでに存在しているか、想定されており、その人たちがビジネスまたはサイトを直接訪問した際に、コンテンツを有用だと感じてくれると思いますか。
- コンテンツは、実体験や深い知識(たとえば、実際に商品やサービスを使用したり、ある場所を訪れたりした経験に基づく特別な知識)を明確に示していますか。
- サイトには主要な目的またはテーマがありますか。
- コンテンツを読み終わったユーザーは、あるトピックについて、目的を果たすのに十分な情報を得たと感じることができますか。
- コンテンツを読んだユーザーは、有益な時間を過ごせたと感じられますか。
有用で信頼性の高い、ユーザーを第一に考えたコンテンツの作成 | Google 検索セントラル | ドキュメント | Google for Developers
検索エンジンに向けたコンテンツの指標
逆に検索エンジンに向けたコンテンツと判断される基準も言語化されています。
以下の質問に「はい」と一部・すべて解答してしまう場合は今回のアルゴリズムによって悪影響があるかもしれません。
- コンテンツは検索エンジンからのアクセスの増加を主な目的として作成されたものですか。
- いずれかが検索結果の上位に表示されることを期待して、さまざまなトピックで多くのコンテンツを制作していますか。
- 多くのトピックについてコンテンツを作成する際、かなりの部分に自動化を使用していますか。
- 価値を付加することなく、主に他の人の意見を要約していますか。
- 既存のユーザー層のためではなく、ただ話題になっているという理由で記事を書いていますか。
- ユーザーがコンテンツを読み終わっても、他のソースからより良い情報を得るために再び検索する必要があると感じさせてしまいますか。
- Google が優先する文字数があるとどこかで聞いたか読んだかしたために、特定の文字数になるように記事を書いていますか(そのような設定は存在しません)。
- 検索トラフィックを獲得できると考えて、実際の経験がないにもかかわらず、ニッチなトピックを扱うことにしましたか。
- 実際には答えがない質問にコンテンツ内で答えることを約束していますか(たとえば、未定のはずの商品の発売日や、映画の公開日、テレビ番組の放送日)。
有用で信頼性の高い、ユーザーを第一に考えたコンテンツの作成 | Google 検索セントラル | ドキュメント | Google for Developers
ヘルプフルコンテンツシステムはどんな仕組みなのか?
ヘルプフルコンテンツシステムは完全に自動化された機械学習モデルによって有用なコンテンツか有用ではないコンテンツかを分類する仕組みになっています。
ただし、有用ではないと分類されたからといって必ず順位が下がることはございません。
ヘルプフルコンテンツシステムは1つのシグナルにすぎず、検索クエリとの関連性が高く、有用であることを示すほかのシグナルがある場合は、ランキング上位になる可能性はあります。
またこのシグナルは重みづけされているため有用ではないコンテンツがサイト内に多いとシグナルの影響を受けやすくなります。
このことからも、有用である・ないの2パターンではなくて数多くのパターンに分けられ重みづけされている気がします。
また有用ではないコンテンツがサイト内にどれだけあるかが重要だということが分かります。
ヘルプフルコンテンツの評価はサイト全体
ヘルプフルコンテンツの評価はサイト全体です。
有用ではないコンテンツが比較的多いと判断されたサイトはウェブ上のほかのコンテンツを優先して表示すべきと判断して、検索結果の順位が下がります。
可能な限り有用ではないと判断されるコンテンツをなくすことが必要です。
そのためには以下の対応をしましょう。
有用ではないコンテンツの削除
有用ではないコンテンツを削除すれば、有用ではないと判断するものがなくなるため評価を上げることができます。
ページなどを削除する際は404コードを返すようにしましょう。
noindexにする
John Mueller氏がエックス上でnoindexの対応でもよいと発信しております。
ただ結局ユーザー的には有用ではないコンテンツにたどり着くため、ユーザーはこのサイトは有用ではないと判断することも考えられます。その影響も踏まえて利用してください。
noindex is fine. Consider if all we see are good signals for your site, that's a good sign. That said, as a user I'd feel kinda weird, you land on a good page, and the rest is bad? Why would you do that? Short-term noindex is a good way to start, but usually it's not a few pages.
— John Mueller (official) · #MaybeABot (@JohnMu) 2022年8月18日
サブドメインは別の評価を受ける
サブドメインのコンテンツが有用でないと判断された場合、メインドメインのランキングに影響はしないようです。(逆でも同じ)
ただし多くの要因にも依存するため確実とは言えないっぽい?
We tend to see subdomains apart from root domains but it can also depend on many factors.
— Danny Sullivan (@dannysullivan) 2022年8月18日
改善効果は数か月後に及ぶ
有用ではないコンテンツを削除したりnoindex対応をした場合、検索順位の改善まで数か月後になるようです。
有用ではないコンテンツがしばらくないことが判断できると、有用ではないという分類から外されるからです。
このシステムによって識別されるサイトでは、数か月にわたってシグナルが適用される場合があります。Google の分類器は継続的に実行され、新たにリリースされたサイトと既存のサイトを監視します。有用でないコンテンツが長い間返されていないと判断されると、分類は適用されなくなります。
Google 検索のヘルプフル コンテンツ システム | Google 検索セントラル | 最新情報 | Google for Developers
ヘルプフルコンテンツシステムの順位影響
ヘルプフルコンテンツシステムの導入によって、大きな変動はみられていないようです。
オンライン学習教材やエンタメ、ショッピング、テクノロジー関連は大きな影響を受ける傾向があったそうです。
しかしヘルプフルコンテンツシステムは特定のジャンルとは限らずあくまでも有用ではないコンテンツ・サイトに対して影響を及ぼします。
おそらくこれらのジャンルには、有用ではないコンテンツが多くあったため大きな影響を受けたのかと思います。
ヘルプフルコンテンツシステムの今後のアップデート
Googleは2023年5月10日に今後数か月以内にヘルプフルコンテンツシステムのアップデートについて発表しました。
内容としては、個人または専門家の観点から作成されたコンテンツをより深く理解するシステムにアップデートをするみたいです。
フォーラムのスレッドのコメントやあまり知られていないブログの投稿、またトピックに関する独自の専門知識を含む記事など見つけにくい場所に存在するものも有用であれば表示するようになるそうです。(嬉しい)
TOPIC:古いコンテンツを削除しないこと
2023年8月9日ごろにエックス上でDanny Sullivan氏が「Googleが古いコンテンツを好まないとなんとなく信じているからといって、サイトからコンテンツを削除しているのですか?そんなことはありません。私たちの指導はこれを奨励するものではありません。古いコンテンツもまだ役に立つ可能性があります」と発信しました。
Are you deleting content from your site because you somehow believe Google doesn't like "old" content? That's not a thing! Our guidance doesn't encourage this. Older content can still be helpful, too. Learn more about creating helpful content: https://t.co/NaRQqb1SQx
— Google SearchLiaison (@searchliaison) 2023年8月8日
なぜこうゆう話になったかというと、GizmodoのCNETが何千もの古い記事を削除したことがきっかけでした。
削除した理由として今回のヘルプフルコンテンツシステムが1つ関わっています。
古い記事など情報の鮮度が低いものやライバルの影響で相対的に検索結果の順位が下がることがあります。
順位が下がるということは検索エンジンはユーザーにとって価値がないと判断したと解釈することができます。
つまりCNETは過去の何千もの記事は有用ではないためヘルプフルコンテンツシステムによってサイト全体の価値も下がったと考えたわけです。
そういった背景がありDanny Sullivan氏は古いコンテンツも役に立つ可能性があるから削除しないでと発信しました。
確かに古い記事だから順位が下がりトラフィックが減ったとしてもそれを閲覧する人にとって有用ではないとは判断できません。
あくまでもヘルプフルコンテンツシステムは訪問した際にユーザーが有用だと感じるかが論点になってきます。
他社などの影響により相対的に順位が下がってきたから有用ではないとは判断できないことにご注意ください。
まとめ
ヘルプフルコンテンツシステムとは、訪問者に満足感を与えているコンテンツを高く評価し、訪問者の期待に応えていないコンテンツとの差別化を図ることを目的としています。
今後もアップデートがあるため今回紹介した内容とずれてくる部分はあるかと思いますが、価値の有用なコンテンツを上位表示したいというGoogleの考えは変わりません。
なので私たちができることとしては、まずは言語化された指標に対して「はい」と言えるようなコンテンツを作成することです。(このページは皆さんにとって有用でしたか心配です)
あざした。
そのほかのコアランキングシステム
RankBrain(ランクブレイン)とは? RankBrainの対策はないことまで説明 - SEOと旅行とか
完全一致ドメインシステム(ExactMatchDomains : EMD)とは? - SEOと旅行とか
完全一致ドメインシステム(ExactMatchDomains : EMD)とは?

完全一致ドメインシステム(Exact Match Domains)とは?
低品質な完全一致ドメインを検索結果の上位表示させないアルゴリズムです。
英語圏では、検索クエリをそのままドメイン名に使えるためよく使われている技術でした。
例えばSEOについてのサイトだった場合は、「howtoseo.com」など検索クエリと一致したドメイン名が対象になります。
amazonというクエリだったら「amazon.com」とかも完全一致ドメインです。
なぜ完全一致ドメインの対策が必要なのか
Google のランキング システムは、ドメイン名に含まれる単語を、コンテンツが検索に関連しているかどうかを判断するための多くの要素の一つとみなしています。
出典:Google 検索ランキング システムのご紹介 | Google 検索セントラル | ドキュメント | Google for Developers
Google公式がいうように、ドメイン名も関連性を測る指標として考えられています。
しかし、完全一致ドメインの影響は強く検索クエリと関連しないコンテンツや薄っぺらい低品質なコンテンツでも検索結果の上位を獲得できる状態でした。
こうなればユーザーは求めている情報が手に入らずユーザー体験が悪くなってしまうため対策する必要がありました。
完全一致ドメインによってどうなったのか
2012年9月29日にMattCutts氏が低品質な完全一致ドメインを追求することと、英米圏のクエリ0.6%に影響があることをTwitterに発表しました。
Minor weather report: small upcoming Google algo change will reduce low-quality "exact-match" domains in search results.
— Matt Cutts (@mattcutts) 2012年9月28日
New exact-match domain (EMD) algo affects 0.6% of English-US queries to a noticeable degree. Unrelated to Panda/Penguin.
— Matt Cutts (@mattcutts) 2012年9月28日
導入後、SEOMozを見ると順位変動があったことが分かります。
どういったドメインが影響を受けたのか興味がある方は、SEOMozのリンクから飛べます。

日本で日本語のサイトをやっているのであれば、関係ない話であまり日本では注目されませんでしたが海外ではかなり大きなアップデートだと認識されていたみたいです。
2023年の今、日本で完全一致ドメインシステムは導入されているのか。
海外SEO情報ブログの鈴木様がJohn Mueller氏にGoogle+のハングアウトでこの件について確認した記事が2013年6月28日に公開されておりました。
EMDアップデートは日本語ドメイン名にも影響を与えているのか?
結論100%断定はできないがほかの言語にも拡大しており、おそらくIDNも検出している可能性があるということです。
John Mueller氏でも確信はないということなので、日本語ドメインにも適用されているのかは分からない状況ですが、可能性はあるので導入された前提で考えておくのがよいかと思います。
完全一致ドメインだからといって順位が下がることはない
マストドンで2023年2月17日に完全一致ドメインのクエリの順位が1位から100位以上に下がったと苦言を発信する方がいました。
私は www.cbd-uk.com を所有していますが、最新の展開後、「cbd uk」で 1 位から 100 位以上になりました。
これによりトラフィックと売上が減少しました。このままでは、ビジネスも崩壊してしまうでしょうか? 私のドメインがEMDだからGoogleは私にペナルティを課さないのでしょうか?この会社は父がガンになった後に立ち上げた会社で、父も助けられました。この場合は、最初からやり直す必要があります。
出典:Google Says An Existing Site Won't Drop In Rankings Just Because It Uses An Exact Match Domain
この発信に対し、John Mueller氏は「EMDを使用しているからといって、既存のサイトのランキングが下がることはありません。そのような変更はほかの理由によるものです」と答えております。
完全一致ドメインシステムの論点は、「低品質」な完全一致ドメインに対しての対策です。
2023年の今、既存のサイトが完全一致ドメインだからという理由で順位が下がることありません。
おそらく他のアルゴリズムによって順位が低下してしまったことが考えられます。
例えばスパムリンクやウェブスパムなど。
完全一致ドメインシステムに対してできること
低品質な完全一致ドメインを検索結果の上位表示させないアルゴリズムでした。
私たちができることは、完全一致ドメインであっても高品質なコンテンツを作ることだと思います。
こちらの情報を参考に以下指標にアプローチすることが大切です。
- コンテンツの自己評価を行う
- 優れたページエクスペリエンスを提供する
- ユーザーを第一に考えたコンテンツに焦点を当てる
- 検索エンジンのためのコンテンツ作成を回避する
- E-E-A-Tと品質評価ガイドラインに則ったコンテンツを作成する
そのほかのコアランキングシステム
ヘルプフルコンテンツシステムとは?仕組みから詳細まで説明 - SEOと旅行とか
RankBrain(ランクブレイン)とは? RankBrainの対策はないことまで説明 - SEOと旅行とか
フレッシュネスシステム(Freshness system)とは?上位表示される仕組みを解説 - SEOと旅行とか
BERTアップデートとは?どんな仕組みでSEOへの影響を解説 - SEOと旅行とか
RankBrain(ランクブレイン)とは? このページで完結すべてわかる!

RankBrainについてGoogleから具体的な情報もなく、いろいろなメディアを見て学んでいました。
でも若干それぞれの内容が異なっていたり、仕組みについての対策ポイントが正しいとは思えないこともありました。
何よりなんの情報をみてそこまで言い切れるのか?という部分もあって自分なりに調べた結果RaknBrainを最適化するための対策なんてないというのが自分の結論です。
ただコアランキングシステムの一部として、検索の仕組みを理解しておくことは何よりも重要です。
今回は僕が何よりも信頼している海外SEO情報ブログ様のGoogleのRankBrainアルゴリズムに最適化する唯一の方法とは?で紹介されていた以下の情報から学習しました。
▼Dany Sullivan(ダニー・サリヴァン)氏が書いたSELの記事
Meet RankBrain: The Artificial Intelligence That's Now Processing Google Search Results
FAQ: All about the Google RankBrain algorithm
Google uses RankBrain for every search, impacts rankings of "lots" of them
▼AJ Kohn(AJ・コーン)氏の記事
詳しく知りたい方はぜひこちらの記事を読んでみてください。
RankBrain(ランクブレイン)とは?
RankBrainとは検索結果の改善を目的として、Googleが開発したディープラーニングアルゴリズムです。
Google検索ランキングシステムのコアランキングシステムとして紹介されていることからRankBrainは検索順位において重要なことだと分かります。
Googleではこのように紹介されています。
RankBrain は、単語がコンセプトにどのように関連しているかを理解するための AI システムです。コンテンツが他の単語やコンセプトに関連していることを理解することで、検索に使われた単語がすべて正確に含まれいなくても、関連するコンテンツをより適切に表示できるようになります。出典:Google 検索ランキング システムのご紹介 | Google 検索セントラル | ドキュメント | Google for Developers
私たちの検索クエリからその検索意図をくみ取って、ユーザーに最適なコンテンツと関連付けをしてくれています。
例えば私は岐阜生まれなので「岐阜のサッカーチーム 結果」と調べてみると画像のようにFC岐阜という単語がなくてもFC岐阜の試合結果が見たいんだなと解釈して最適なコンテンツに関連付けてくれています。(本来こんな調べ方する人はいないと思いますが)

なぜできるかというと、言葉をコンピュータが理解できるベクトルと呼ばれる数学的実体に変換をしているからです。
馴染みのある単語を見つけたときは、コンピュータはどのような単語が似た意味を持つのかを推測して、それに応じてフィルタリングをすることでこう言った検索クエリなども効果的に処理ができるようになります。
「関連性の高いコンテンツを検索結果に表示してくれている」と書かれている記事も多くありますが、僕はあえて「最適なコンテンツを関連付けている」と言いいます。
RankBrainは、Google検索ページにどのような結果が表示されるか、またその結果がどこにランク付けされるかを決定するアルゴリズムに入力される「数百」のシグナルの1つであるとコラード氏は述べた。出典:Meet RankBrain: The Artificial Intelligence That's Now Processing Google Search Results
細かい話ですが、表示してくれているというのは自分的にRankBrainだけで言葉を解釈して最も関連したコンテンツを返しているように捉えてしまいます。
実際はコラード氏が述べているように結果をランク付けするアルゴリズムに入力される1つにしかすぎません。※シグナルとは、Googleがウェブページのランク付けをするために使用するための変数みたいなもの
ちょっと自分の言いたいことだったので脱線しましたが、RankBrainは「検索クエリからその検索意図をくみ取って、ユーザーに最適なコンテンツとの関連付けをしてくれている」ということです。
なぜRankBrainが必要なのか
当時は、Googleがクエリを改良するためにステミングリストや同義語リストを作成して取り組んでおりました。
※ステミングとは語形変化を取り除き、同一の単語表現に変換する処理
問題になるのは今まで見たことのないクエリはリストから抜けてしまうことです。
Googleが1日に30億件の検索を処理していて、2007年にクエリの20~25%は今までにないクエリと発表しました。
2013年には15%まで下がりましたが、それでも4億5000万件は今までにないクエリです。
それらのクエリは結果的に対策ができないので、ユーザーにとっては求めていた情報が得られずユーザー体験が悪くなってしまいます。
そういった事象からユーザーの検索意図をくみ取ったコンテンツ提供が必要だったためRankBrainが生まれたのかと思います。
RankBrainはすべてのクエリで処理されている
2015年10月にGoogleはBloombergに対し、今まで見たことのないクエリ15%のうち大部分がRankBrainによって処理されたと語っていました。
2016年6月にGoogleが処理するすべてのクエリにRankBrainが使用されているというニュースが発表されました。
その続きとしては、すべてのクエリでRankBrainは使用するが多くのクエリの検索結果のランキングを変更するということです。
皆さん一度はRankBrainを聞いてシグナルなの?なんかユーザーのクエリをよりよく理解するためだけに使ってるんじゃないの?と思ったと思います。
この考えはあってそうな気もします。
Googleはすべてのクエリの検索意図をより理解するためにRankBrainをツールとして利用し、その後必要に応じてランク付けに影響を与えてるのかなと思います。
ただ、こればっかりは真相は闇の中です。あくまでも自分はそう思いました。
3番目に重要なシグナル
GregCorrado氏はRankBrainは検索クエリの結果に寄与する3番目に重要なシグナルになったと述べています。
そもそもGoogleが重要性をどう測定して判断したのか分かりません。
Googleの検索品質シニアトランジストであるAndrey Lopattsev氏がAmmon Johns氏らとのQ&Aで述べた発言があります。
AJ Kohn(AJ・コーン)氏は、この解答からこう考察しております。
RankBrain は多くのクエリで「呼び出された」可能性がありますが、結果に重大な影響を与えていない可能性があります。
または、技術的な話になる場合は、RankBrain によって結果の並べ替えが発生していない可能性があります。したがって、「重要性」は影響力ではなく、頻度によって測定された可能性があります。出典:The RankBrain Survival Guide
自分も解答からのニュアンス的にRankBrainが利用される頻度によって重要性を判断した感じがしました。
先ほどのようにすべてのクエリで処理されているという記事からもその考え方で間違っていないのではないかと感じます。
ちなみに1,2はコンテンツとリンクだとこの動画で解答していました。
どちらが1位か不明ですが…
といいつつも
その後、John Mueller氏がランキング要因重要度にトップ3など存在しないことを発言しております。
そもそもランキング要因の重要度はGoogleが公式で定めているのか、個人の考え方なのかも分かりません。
それにクエリによって重要となるシグナルも変わるので、RankBrainやリンク・コンテンツが1位だ2位だと順位をつけること自体間違っているようにも思えます。
リンクもコンテンツも大切なのは間違いないですが…
対策なんてない
RankBrainの言葉を数学的なベクトルに変換して、クエリの意味の理解しコンテンツと関連付けるアルゴリズムです。
RankBrainのベースとなっているベクトルを理解しても対策できることは何もないと思います。
ユーザーのクエリを理解してコンテンツを関連付けてくれることは私たちのメリットでしかありません。
私たちは今までと変わらずやることは
・Googleがコンテンツの意味をよりよく理解できるように文章にすること
・高品質なコンテンツを作りユーザー体験をよくすること
だと思います。
最終的には優れたコンテンツが上位に来るように考えられています。
私たちはRankBrainのために何かするのではなく、ユーザーのためにどんな品質の高いコンテンツを提供できるかに焦点を当てて進むべきだと思います。
そのほかのコアランキングシステム
ヘルプフルコンテンツシステムとは?仕組みから詳細まで説明 - SEOと旅行とか
完全一致ドメインシステム(ExactMatchDomains : EMD)とは? - SEOと旅行とか
CoreWebVitalsのFIDに代わるINPとは?FIDから説明します
INPをCoreWebVitalsに導入
2024年3月よりCoreWebVitalsの指標がFID(First Input Delay)からINP(Interaction to Next Paint)へ変更されます。
- CoreWebVitalsとは
- FIDとはなにか
- INPとはなにか
- INPとFIDの違い
について書いていこうと思います。
CoreWebVitalsとは?
2020年にウェブページの各種品質シグナル(指標)を提供するCoreWebVitalsを導入しました。
CoreWebVitalsには3つの指標があります。
- LCP(Largest Contentful Paint):そのページでメインとなるコンテンツ)が表示されるまでの時間
- FID(First Input Delay):初回入力までの遅延時間
- CLS(Countent Layout Shift):コンテンツがどれだけずれたか
CoreWebVitalsは、ページエクスペリエンスの1つでありGoogle公式からは改善することを強くおすすめされています。
ページの読み込みパフォーマンス、インタラクティブ性、視覚的安定性に関する実際のユーザー エクスペリエンスを測定する一連の指標です。検索結果でのランキングを上げ、全般的に優れたユーザー エクスペリエンスを提供できるよう、サイト所有者の皆様には、Core Web Vitals を改善することを強くおすすめします。
出典:Core Web Vitals と Google 検索の検索結果について | Google 検索セントラル | ドキュメント | Google for Developers
しかしCoreWebVitalsは独立したランキングシステムという仕組みではなく、ランキングを上げる構成要因となっています。
Google検索はページエクスペリエンスの評価よりも、検索ワードに関連性の高いコンテンツを基準に表示するようになっています。
関連性の高いコンテンツの中でページエクスペリエンスを実現されているような場合はそれらよりもランキングが上がることにつながるよっていう認識でいましょう。
FIDとはなにか
FID(First Input Delay)とは、初回入力までの遅延時間です。
初回入力とはリンクのクリックやボタンタップなどユーザー側がアクションを起こしたことです。
ユーザーが最初に入力したときから、その入力に応じたブラウザーが実際に処理を開始するまでの時間です。
ボタンをクリックしたのに、全く動かなかったらユーザー体験は悪いですよね。
FIDは読み込んだ最初の入力がどれくらい遅延するかを見てユーザー体験のよし悪しを判断しています。
なぜ遅延が起きるのか?
ブラウザーにはメインスレッドといって描画したりしてくれるやつがいます。
このメインスレッドが何かの作業でめっちゃ忙しかったらユーザーの操作に応答できません。これが遅延です。
めっちゃ売れるお店には料理人一人しかおらず料理してたら新規のお客様のオーダーは料理が完成したあとみたいなのが遅延。
お客様からしたら「すみませーん」って言ってから料理人がオーダーを聞きに来るまでが遅延時間です。
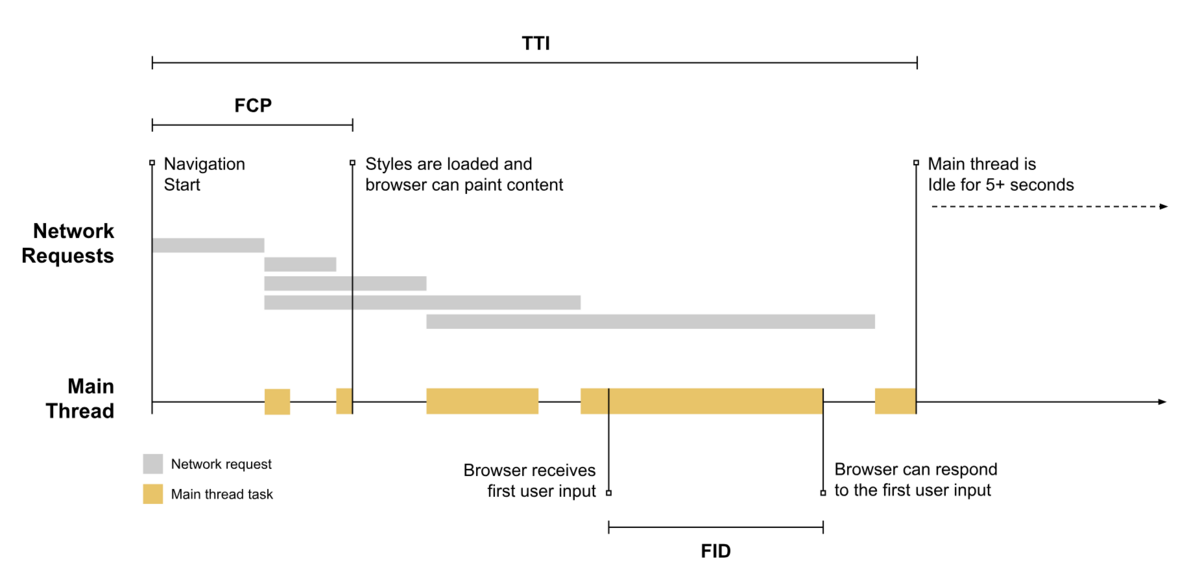
出典:Interaction to Next Paint (INP)
急に英語の図ですが、FIDの部分で「Browser receives first user input」というブラウザーが最初にユーザーから入力を受けたときに、メインスレッドは今稼働中なので応答できません。
オレンジの処理が終わったところで応答ができるためその時間がFIDとなります。
FCP(First Content Paint)の段階でユーザーには一部コンテンツが表示されているので入力は可能です。
ちなみにこの原因は、大体JavaScriptの解析と実行でブラウザーが忙しくて応答できないことが多いですね。
詳しくはFirst Input Delay (FID)をご覧ください。
INPとはなにか
INP(Interaction to Next Paint)とは、ユーザーインタラクションに対するページの全体的な応答時間を評価した値です。
ページの中にあるすべてのインタラクションで一番悪い数値がINPとして報告されます。
インタラクションとは何か

出典:Interaction to Next Paint (INP)
上記GIFのように右は入力に対して即座に視覚的なフィードバックをしています。
左は入力しても遅延しユーザーは壊れていると考えて何度もクリックして意図しない応答が発生しています。
このようにインタラクションとは、ユーザーの入力に対して視覚的フィードバックを返すまでの範囲を指します。
インタラクションには大きく3つの指標で構成されています。

出典:Interaction to Next Paint (INP)
- 入力遅延:ユーザーが操作し、実行されるまでの時間
- 処理時間:コードの処理にかかる時間
- プレゼンテーション遅延:ブラウザが結果を表示するまでの時間
これら3つの指標の合計時間がINPとして評価されます。
INPとFIDの違いはなにか
2つあります。
1点目は計測する範囲です。
FIDは最初の入力から応答するまでの時間(イベントハンドラーの処理を開始するまでの時間)でしたが、INPは入力してから視覚的フィードバックされるまでの時間です。
FIDでは応答するまでは早いけど結局レンダリングしてペイントするまでが遅くても評価は高いです。
実際にユーザーは視覚的フィードバックがあった時に応答を認識するのでINPのほうがよりユーザー体験を評価できてるかなと思います。
2点目は計測するタイミングです。
FIDはページに流入してきて初めての入力だけで評価をします。
INPはページすべてのインタラクションで評価をします。
FIDでは最初の入力さえ早ければいいので、途中のコンテンツがインタラクションのイメージ図でもあったようにクリックしても応答が悪くてもユーザー体験がよいと評価されてしまいます。
INPはそれらもくみ取って評価するのでよりユーザー体験を評価できていると思います。
まとめ
INPの導入までまだまだ猶予はあります。(2024年3月より導入)
この機会にLight houseなどを使って改善してみてはどうでしょうか。
実際INP, FIDも改善すべき点はJavaScriptだったりします。
自分の経験上、JavaScriptのサイズが大きかったり1つの処理がめちゃめちゃ長いなんてこともありました。
そもそもこのファイルは必要なのか?
最初に読み込む必要があるのか?
ファイルを分割できないのか?
処理を細かくしてメインスレッドを空けることができないのか?
などを考えてみると改善できる点はあるんじゃないでしょうか。
WebWorkersなどでバックグラウンドでの実行もありますがDOM操作ができないためあまり使えていませんでしたが今後は挑戦していきたいです。